The Astro home robot has been turning heads ever since Amazon unveiled the device last fall. Customers can ask the pet-sized robot to patrol the house, check on pets, handle video calls, order groceries, and even fetch a drink. But few people are more amazed by its capabilities than the scientists who brought it to life.
“Even as someone who works on this kind of thing for a living, it feels like magic,” says Wontak Kim, an Amazon audio engineer whose team helped teach Astro to accurately process audio.
It may feel like magic, but Astro’s ability to respond to requests in a busy room is actually the result of countless hours of dedicated work. Kim’s team, part of Amazon’s Devices and Services organization, includes acoustic scientists and engineers at Amazon’s audio lab in Cambridge, Massachusetts. Working with colleagues in Sunnyvale, California, and Bellevue, Washington, they designed and built Astro’s audio features, including speech recognition and audio and video calling. They knew that, for the household robot to be successful, it had to be able to understand and process requests audio clearly. But not only that; Astro’s video calling feature had to run pretty much in real time for customers to be able to use it.
“Humans cannot tolerate latency with audio,” says Mrudula Athi, an acoustic scientist on Kim’s team. “Even 20 milliseconds of lag are immediately noticeable. So, for Astro, we needed to process and clean up 125 audio signal frames per second.”
The magic is in untangling the soundwaves

Astro’s audio features utilize Amazon’s Alexa, the company’s voice AI. On any Alexa-enabled device, Alexa doesn’t automatically identify speech the way we would when someone is talking to us. As you make a speech request, the sound waves bounce off of walls and ceilings on their way to the device’s microphone.
With Astro, this challenge is compounded by the fact the robot moves around the home. For the robot to satisfy customers, it needed to accurately process speech requests without being distracted by pets or other common household noises, the subtle sounds of the electric motors that power it, or the music or other audio that it plays. For example, Amit Chhetri, a senior principal scientist on the Sunnyvale team, says that when Astro is moving over a tile floor, “the level of wheel noise at the microphones is even higher than the speech.”
The magic is in untangling all of the extra sound.
“If you send all of that noise to the speech-recognition application, it’s not going to perform very well,” says Athi. “Our job is to take these microphone signals and make sure they’re cleaned up enough that Alexa can perform at a level that results in a good customer experience.”
All of this sound sorting must also happen quickly.
This is a tough problem, and Amazon assembled some serious brain power to solve it. The Astro audio team included acoustic scientists well-versed in the physics of sound, applied researchers building algorithms to manipulate soundwaves, and software engineers who weave those algorithms into powerful code.
Taking AI-driven algorithms to a new level
The team first focused on muting background noise during audio and video calls, so that people can speak and understand each other even as the robot navigates a noisy space. To make it all work at the fast speeds required, the team used an AI-driven algorithm called a deep neural network (DNN), which is often used to address audio and computer-vision problems. But they took it to a new level. Chhetri, specifically, designed a new network architecture that both reduces background noise, and de-reverberates speech, allowing Astro to handle calls.
Using simulated data
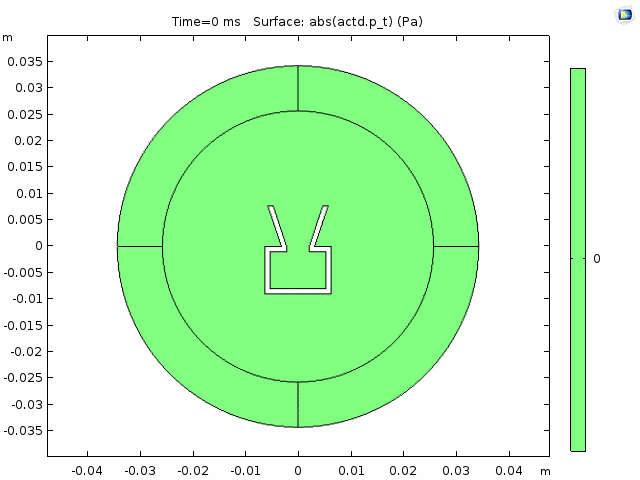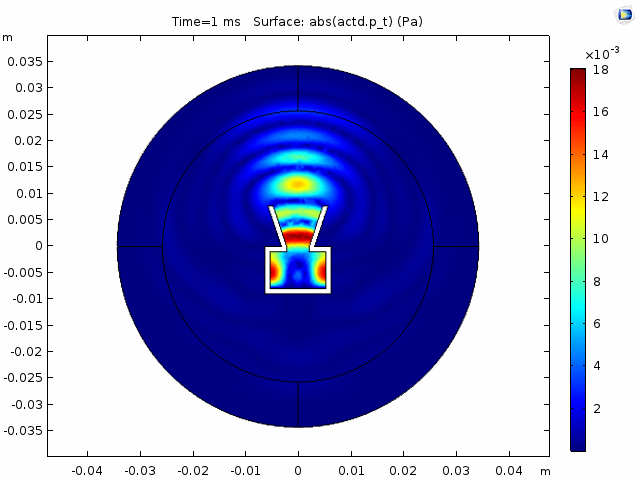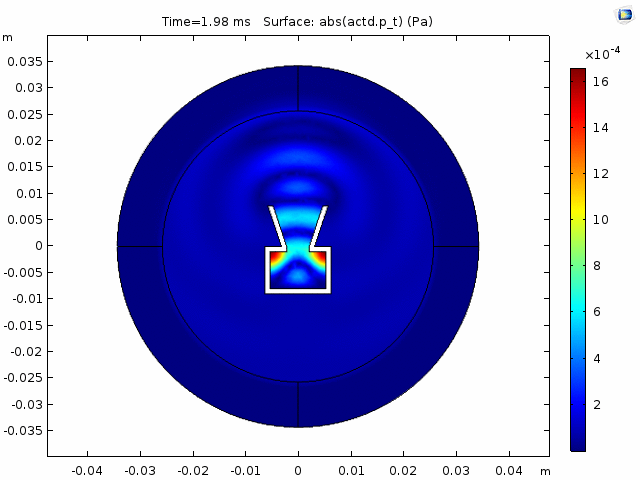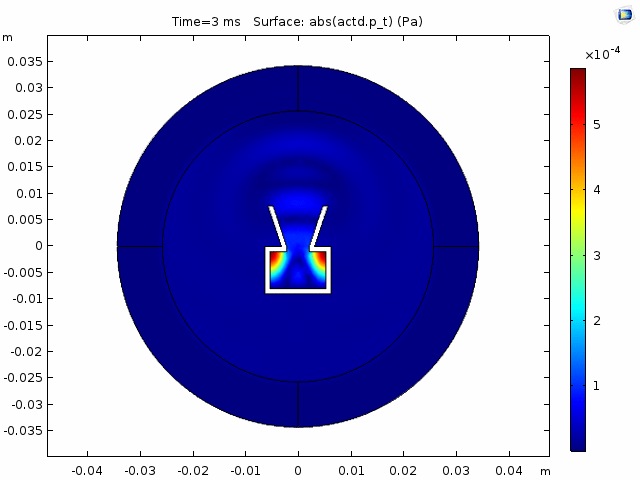
DNNs—especially ones as advanced as the one Chhetri, Athi, and the team developed—typically require lots of data to train. That’s where the team’s audio simulation expert came in. Because of the data he generated, Athi says the engineers were able to rely on the simulated voice of “somebody speaking from different positions in different kinds of rooms, with different levels of artificial room noise.” Amazon audio scientists typically use simulated data for projects like helping devices locate the sources of sound. But with Astro, the team had to go a step further. Because the robot makes its own noise, they needed even more Astro-specific data to build their speech-enhancement model.
Another Amazon team had recorded audio of Astro producing distinct noises while driving around a home in all sorts of scenarios. Athi says this data was perfect for their speech-enhancement problem. So, she mixed it with speech datasets she’d assembled to train the robot, and solved the problem.
A “state of the art” solution

The audio team was happy with the result, but now they had to fit all this code inside the robot, another unique challenge. But again, teams from Amazon’s audio labs across the country stepped up. The result, Athi says, is incredibly advanced.
“The amount of noise reduction we’re getting with the speech-enhancement performance we have, while being able to run in real time, not in the cloud, but on-device… that whole thing put together is pretty state of the art,” she says.
Fitting Astro’s speech-enhancement feature on the device is one of the things which Athi says she’s most proud of in her professional career. But Kim, Athi, Chhetri, and the rest of the audio team aren’t stopping any time soon. They’re continuing to improve Alexa’s speech recognition, Astro’s speech enhancement, and they have a number of projects underway that they’re excited to bring to customers.
“We are very proud to be working in this audio field for Amazon,” Kim says, “and for customers.”
Want to learn more about all the fun, convenience, and security that Astro delivers? Check out the updates Amazon announced to the home robot at the Devices and Services fall launch.
Illustration by Mojo Wang.